[2024-07-28] 새로운 Loss function 만들어보기
…기계학습으로 그림체를 분류하겠다 선언한지 어언 2개월, 결과적으로 실패했다.
원인은 여러 가지가 있을 수 있지만, 내가 봤을 땐 두 가지 이유다.
- 데이터셋이 너무 적다
- 데이터셋이 정제되지 않았다.
이미지가 적기도 하고, 또 그림체라는게 사람 주관인지라 내맘대로 분류해서 넣어놨더니 컴퓨터가 혼란스러워하는 것 같다.
아무튼 결과적으로 실패했으며, 부수적으로 얻은게 몇개 있긴 하지만 열심히 구른 GTX 1080에게는 조금 미안하게 됐다.
아무튼 그래서 2개월동안 놀았던 것은 아니고, 지금 그림의 심미성을 판단하는 모델을 학습시키고 있다. 심미성도 주관적인 영역이라 조금 애매하긴 하지만, 적어도 그림체보다는 분류하기 훨씬 수월했던지라 나름 이미지 정제도 잘 된 것 같다.
그래서 오늘의 본론은, 이걸 학습하다가 새로운 Loss function을 만들어 봤다는 것이다.
현재 학습하고 있는 모델은 그림의 심미성을 0부터 1까지의 값으로 표현하는 회귀 문제를 다루고 있다. 그리고 대개는 이런 경우 mse나 mae를 사용한다.
물론 둘 다 좋은 함수기는 하지만, 나는 갑자기 힙스터 감성이 살아났고, 새로운 Loss function을 찾아 나서는 여정을 떠났다.
결과적으로 둘을 대체할 수 있는 함수들이 몇 개 있긴 한데, 실제로 돌려보니 체감상 영 별로였다. 그러면 어쩌겠는가, 마음에 드는 게 없으면 새로운 Loss function을 만들어야 한다.
나는 다음과 같은 함수를 원했다.
- 미분 가능할 것
- mse마냥 기울기 값이 극단적으로 커지지 않을 것
- error값에 따라 loss function의 기울기를 조절할 것
많은 함수를 시험해 봤고, 결과적으로 다음과 같은 함수로 최종 결정했다.
def smooth_loss(error, delta=1.0, alpha=2.0):
grad = lambda x: delta * np.exp(1 - np.abs(x)) * x
gradient = grad(np.clip(error / alpha, -1, 1))
return gradient * error
뭔가 복잡해보이기는 한데, 그래프로 보면 막상 복잡하진 않다. 파라미터 값은 여러 값을 시험해 보고 가장 그럴듯한 값으로 기본값을 세팅했다.
설명하자면, alpha 값을 기준으로 작은 쪽은 지수적으로 기울기가 증감하며, 큰 쪽은 선형적인 기울기를 갖는 함수다. 즉 mse와 mae를 적절하게 합쳤다고 말할 수 있다.
에러가 커지면 선형적인 기울기를 가지므로 폭주를 막을 수 있고, 에러가 작으면 빠르게 감소시킬 수 있다. 물론, 미분 가능하다.
미분이 가능한 이유는, alpha값이 변곡점이기 때문이다. 변곡점을 기준으로 선형과 비선형을 합쳤으니 미분이 가능할 수밖에.
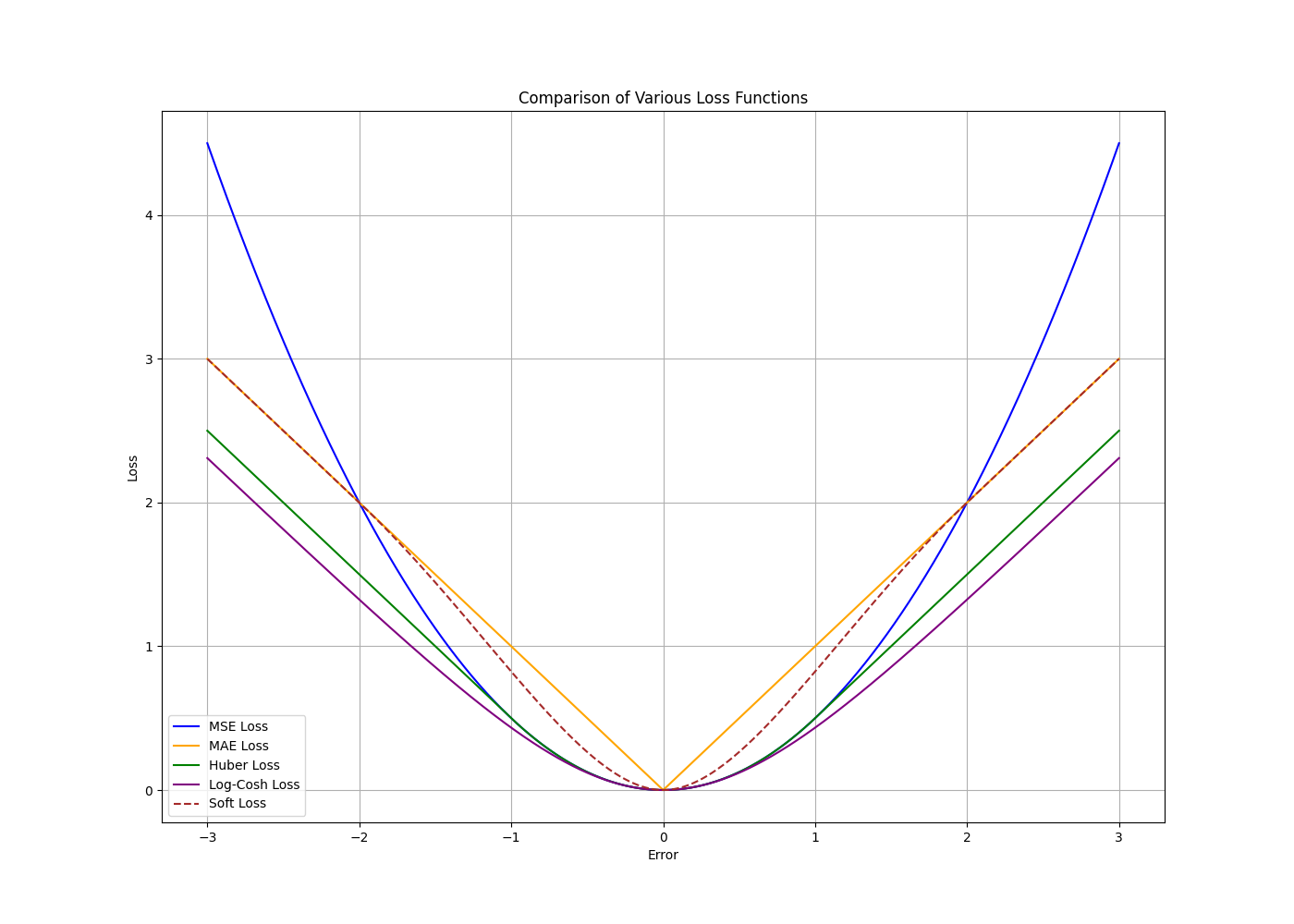
실제 그래프의 모습이다. 점선이 새로 만든 거고, 나머지는 기존의 것들이다. 보면 굉장히 흥미로운 형태다. 문제가 있다면 mse에 비해 작은 오류에서 상대적으로 큰 값을 갖는다는 정도?
또 함수가 복잡하다 보니 성능 이슈가 있을 수 있다. 다른 함수는 비교적 간단한데 지수함수를 섞어놨으니 컴퓨터가 힘들어할 수도 있다. 근데 딥러닝 돌릴 컴퓨터 정도면 이정도는 해줘야 하는거 아닌가?
아무튼 현재 이 함수를 이용해서 학습을 돌리고 있는데, 체감상 다른 것들보다 수렴이 잘 되는 것 같은 기분이 든다. 몇번 사용 안해봐서 실제로 잘 수렴하는건진 모르겠는데, 당장은 만족한다.
그리고 이건 잡담이지만 왜 pytorch가 tensorflow를 앞지르고 있는지 알 것 같다. 메모리 효율이 압도적인게, tensorflow에서는 메모리 초과로 절대 작업하지 못할 것을 pytorch에서는 수월하게 해낸다. 이게 최신기술의 힘…!